

APPLICATION
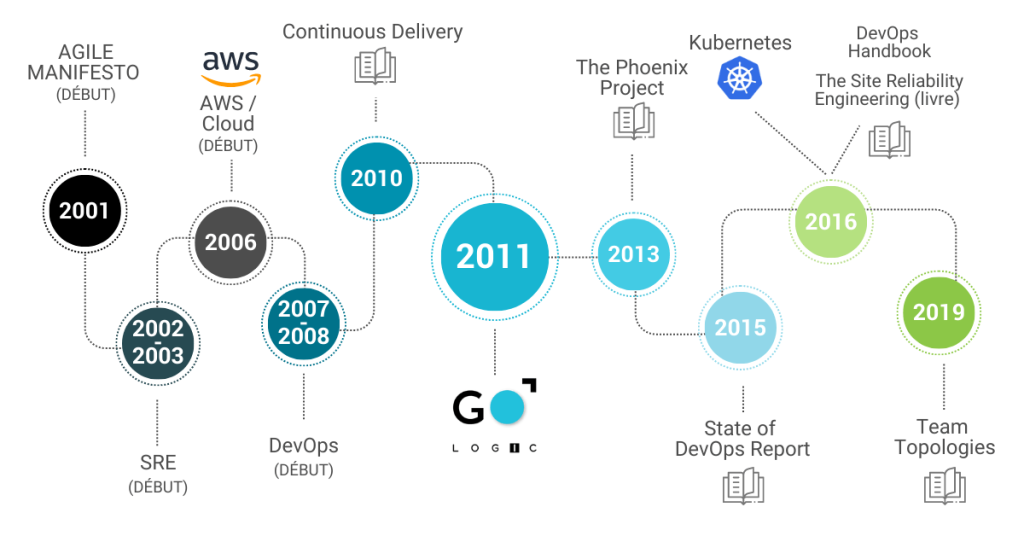
Une brève histoire DevOps et SRE
Entre 2001 et 2008, le développement logiciel en mode Agile était dans tous les esprits et son adoption gagnait énormément de terrain au fil des années. Cependant, les départements d’opérations logicielles (Ops) agissaient comme un goulot d’étranglement dans le cycle de livraison de logiciels. Même si une équipe de développement travaillait par petits incréments, à la fin, un déploiement en production pouvait prendre des semaines, voir des mois.
En 2008, lors de la Conférence Agile (Toronto), Patrick Dubois présentait Agile Infrastructure & Operations, deux idées clés pour résoudre l’impasse Agile avec les opérations informatiques : déployer souvent et créer des équipes multidisciplinaires. C’était la naissance du DevOps, et ces deux idées sont toujours des valeurs fondamentales.
À cette époque, le DevOps était davantage un sujet de conférence, qu’une pratique bien répandue. Mais cela allait changer ; en 2010, David Farley et Jez Humble publiaient Continuous Delivery et donnaient ainsi le ton sur ce qu’une équipe DevOps multidisciplinaire devait faire pour déployer des applications aussi souvent que possible. C’est ainsi que l’âge d’or du DevOps a commencé.
Le SRE (Site Reliability Engineering) a précédé le DevOps de plus de 5 ans (créé en 2003 chez Google) en développant une fonctionnalité qui consistait à construire un framework pour gérer des systèmes à grande échelle. Cette bonne méthode était nécessaire pour assurer la fiabilité et la haute disponibilité promises à leurs clients, en accordant une attention supplémentaire.
Entre 2003 et 2016, l’approche SRE a été principalement adoptée par de grandes entreprises telles que Google, Facebook, Uber et Netflix. L’idée était de créer une équipe entre le développement et les opérations pour s’assurer que les systèmes étaient toujours accessibles (disponibilité) et à l’épreuve des pannes (fiabilité). Le SRE est à la fois une équipe, les outils et les pratiques que l’équipe utilise pour atteindre son objectif.
DevOps et SRE ont évolué presque en parallèle ; certains bataillant pour savoir lequel est meilleur. Cela a duré jusqu’en 2016, jusqu’à ce que les ingénieurs chez Google publient le livre SRE qui affirme :
“Class SRE implements interface DevOps.”
En bref, SRE est une variante du DevOps.
Introduction : La Fin du Mur de la Honte
Pendant des décennies, les équipes de développement et d’opérations IT évoluaient dans des silos séparés, communiquant par tickets et réunions de crise un « mur de la honte » qui ralentissait les déploiements et générait des frustrations. Aujourd’hui, le DevOps et le Site Reliability Engineering (SRE) ont dynamité ce mur. Bien plus que des buzzwords, ces philosophies transforment la façon dont les entreprises construisent, déploient et maintiennent des logiciels fiables, rapides et évolutifs à l’ère du cloud.
Le DevOps incarne une culture d’union entre le développement (Dev) et les opérations (Ops), centrée sur la collaboration, l’automatisation et l’amélioration continue. Il repose sur une automatisation intense des processus via des pipelines CI/CD (Continuous Integration/Continuous Deployment), des outils d’Infrastructure as Code (IaC) comme Terraform ou Ansible, et une supervision avancée avec Prometheus ou Grafana. Cette approche permet des releases fréquents et fiables, réduit les délais de mise sur le marché et améliore la qualité logicielle.
Le SRE, popularisé par Google, va encore plus loin en appliquant une rigueur d’ingénieur à la fiabilité des services. Les SREs utilisent des indicateurs comme les SLIs (Service Level Indicators), les SLOs (Service Level Objectives) et les SLAs (Service Level Agreements) pour quantifier et garantir la disponibilité, la latence et la performance des systèmes. Ils automatisent tout ce qui peut l’être y compris la réponse aux incidents et consacrent idéalement moins de 50 % de leur temps au travail opérationnel, le reste étant dédié à l’ingénierie et l’amélioration proactive.
Cette évolution est rendue nécessaire par la complexité des architectures cloud-native, la conteneurisation (Docker, Kubernetes) et l’exigence croissante de résilience et d’échelle. Elle répond aussi à un besoin business : dans un monde où chaque minute d’indisponibilité peut coûter des milliers d’euros, la fiabilité devient un avantage compétitif majeur.
Cependant, l’adoption de ces pratiques n’est pas sans défis. Elle exige un changement culturel profond, une formation aux nouveaux outils et méthodologies, et une refonte des processus organisationnels. Le DevOps et le SRE ne sont pas des solutions clés en main, mais des voyages qui demandent engagement et adaptation.

DevOps : La Culture de la Collaboration Automatisée – Au-Delà des Outils
Le DevOps est souvent réduit à une collection d’outils comme Jenkins, Docker ou Kubernetes. En réalité, c’est avant tout une philosophie organisationnelle et culturelle dont l’objectif est de supprimer les barrières traditionnelles entre les équipes de développement (Dev) et d’opérations (Ops). Son essence réside dans la création d’un flux de travail continu, depuis l’écriture du code jusqu’au déploiement en production, en passant par les tests et la surveillance.
Les Cinq Piliers Fondamentaux du DevOps (CALMS)
Un cadre utile pour comprendre le DevOps est l’acronyme CALMS :

- Culture (Culture) : C’est le pilier le plus important. Il s’agit de favoriser une culture de confiance, de collaboration et de responsabilité partagée. Les développeurs ne se contentent plus de “balancer du code par-dessus le mur” aux ops. Ils comprennent et assument les implications de leur code en production (performance, sécurité, stabilité). Inversement, les ops participent plus tôt au cycle de vie pour conseiller sur la conception des systèmes. Le blâme est remplacé par une analyse post-mortem sans culpabilité (blameless postmortem) pour apprendre des échecs.
- Automatisation(Automation): C’est le moteur qui rend le modèle viable. L’automatisation est appliquée à tout le pipeline de livraison logicielle :
Intégration Continue (CI – Continuous Integration): Les développeurs intègrent leur code dans un dépôt partagé plusieurs fois par jour. Chaque intégration déclenche une build automatique et une batterie de tests pour détecter les erreurs immédiatement.
Livraison Continue (CD – Continuous Delivery): Extension du CI, le CD assure que le code peut être déployé en production à tout moment de manière sécurisée. Chaque changement qui passe les tests est automatiquement livré dans un environnement de type production.
Infrastructure as Code (IaC): L’infrastructure (serveurs, réseaux, configurations) est gérée via du code et des fichiers de définition (avec Terraform, Ansible, etc.). Cela permet de la versionner, de la tester et de la provisionner de manière reproductible et automatisée, éliminant les configurations manuelles hasardeuses.
3. Lean(Lean): Inspiré des principes de gestion de la production Toyota, le Lean appliqué au DevOps vise à optimiser le flux de valeur pour le client. Il s’agit d’éliminer les gaspillages (tâches manuelles, attentes, retouches) et de travailler en petits lots pour accélérer le feedback et réduire le temps de cycle (lead time).
4. Mesure (Measurement): “On ne peut améliorer que ce que l’on mesure.” Le DevOps s’appuie sur une collecte de données objective à toutes les étapes :
Metrics de Performance : Temps de cycle, fréquence de déploiement, taux d’échec des déploiements, temps de rétablissement (MTTR – Mean Time To Recovery).
Monitoring et Observabilité : Surveiller l’application en production avec des outils comme Prometheus/Grafana pour comprendre son comportement et détecter les problèmes avant les utilisateurs.
5. Partage(Sharing): La boucle de feedback doit être partagée ouvertement dans toute l’organisation. Les succès, mais surtout les échecs et les enseignements tirés, sont communiqués pour que tout le monde puisse en bénéficier et éviter de répéter les mêmes erreurs.
SRE : La Fiabilité Ingéniée par Google
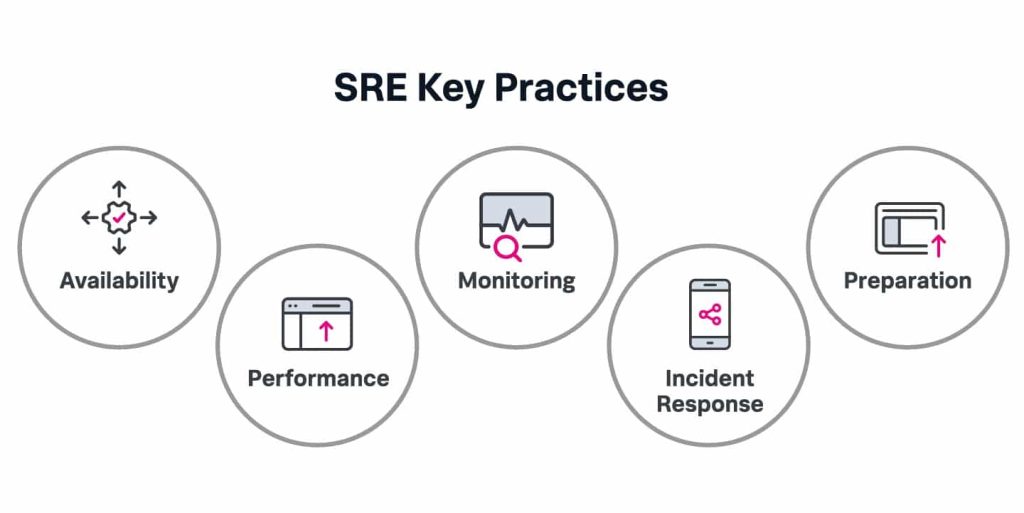
Le Site Reliability Engineering (SRE) est une discipline créée chez Google qui applique une rigueur d’ingénieur logiciel aux problèmes de fiabilité des systèmes à grande échelle en se fondant sur des principes clés comme les SLIs qui mesurent concrètement des aspects comme la disponibilité ou la latence et les SLOs qui définissent des objectifs de performance exigeants que l’équipe s’engage à respecter tandis que les SLAs formalisent ces engagements vis-à-vis des clients avec des conséquences commerciales en cas de manquement
Un concept central du SRE est le budget d’erreur qui représente la marge d’indisponibilité tolérée pour un service sur une période donnée et qui sert de régulateur entre l’innovation et la stabilité en autorisant les déploiements tant que le budget n’est pas épuisé mais en les gelant le temps de rétablir la fiabilité dès qu’il est consommé
La résilience des systèmes est assurée par des designs qui anticipent les pannes avec des mécanismes comme les retry avec backoff pour réessayer intelligemment les requêtes ou les circuit breakers pour isoler les services défaillants et éviter la propagation des incidents et cette résilience est testée en production via le chaos engineering qui provoque des pannes contrôlées pour valider la robustesse des architectures
Enfin le SRE combat le toil qui désigne le travail manuel et répétitif en automatisant tout ce qui peut l’être et en imposant que moins de cinquante pourcent du temps soit consacré à ces tâches opérationnelles pour se concentrer sur l’ingénierie à valeur ajoutée comme la conception de systèmes plus fiables et l’amélioration des outils et des processus.

DevOps ou SRE ?
Premièrement, le DevOps est plus démocratisé aujourd’hui car il n’est lié à aucune organisation ou entreprise, à la différence de la SRE qui est liée fondamentalement à Google. Les rivaux de Google peuvent donc utiliser plus aisément le DevOps que la SRE. Aussi, la SRE n’a pas encore fait l’objet d’une utilisation très développée car le terme DevOps désigne en langage courant toutes les pratiques qui font collaborer opérations et développement, ce qui pourrait donc englober aussi la SRE.
Les ingénieurs DevOps travaillent sur un produit ou une application dans un souci d’optimisation. En utilisant la méthode agile, ils construisent, testent, déploient et surveillent les applications avec rapidité, contrôle et qualité. Le travail d’une équipe DevOps est de rendre l’ensemble de l’organisation plus efficace et automatisée. D’autre part, elle se concentre sur les processus globaux qui devraient aboutir à un déploiement réussi d’un produit.
Une équipe SRE travaille en collaboration avec l’équipe de développeurs. Son objectif est de tirer parti des données opérationnelles et de l’ingénierie logicielle, principalement en automatisant les tâches des opérations informatiques, ce qui accélère la livraison de logiciels. Elle va rationaliser les opérations informatiques en utilisant des méthodes qui n’étaient auparavant utilisées que par les développeurs de logiciels. L’ingénierie de la fiabilité du site se concentre sur le maintien de l’application ou de la plateforme à la disposition des clients : elle se concentre sur les besoins du client en donnant la priorité aux mesures de l’accord de niveau de service, de l’indicateur de niveau de service et de l’objectif de niveau de service.
Pourquoi cette Montée en Puissance ?
La convergence des pratiques DevOps et SRE n’est pas un simple effet de mode. Elle répond à des impératifs business, techniques et économiques profonds qui transforment l’industrie logicielle.
Nécessité Business : La Vitesse sans Compromis
La pression concurrentielle exige désormais une livraison rapide et continue de nouvelles fonctionnalités pour répondre aux attentes des utilisateurs et devancer les concurrents. Cependant, cette accélération ne peut plus se faire au détriment de la stabilité et de la qualité. Les clients tolèrent de moins en moins les interruptions de service ou les régressions. Le DevOps et le SRE offrent le cadre pour concilier ces deux objectifs auparavant contradictoires : vélocité et fiabilité. En automatisant les tests, les déploiements et la surveillance, les entreprises peuvent livrer plus fréquemment tout en réduisant les risques.
Complexité Architecturale : Maîtriser l’Écosystème Moderne
L’avènement des architectures cloud-native, basées sur les microservices, les conteneurs et l’orchestration (Kubernetes), a considérablement augmenté la complexité des systèmes. Gérer manuellement des centaines de services interdépendants, avec leurs propres cycles de déploiement et leurs dépendances, est tout simplement impossible à grande échelle. Le DevOps fournit les outils et pratiques (IaC, CI/CD) pour automatiser la gestion de cette complexité, tandis que le SRE apporte les méthodologies pour garantir la résilience et la observability de ces systèmes distribués et dynamiques.
Impératif Économique : Le Coût Exorbitant de l’Indisponibilité
Dans un monde où les activités critiques dépendent de services en ligne, chaque minute d’indisponibilité se traduit par des pertes directes de revenus, une erosion de la confiance des clients et des dommages à la réputation de la marque. Des pannes très médiatisées, comme celles d’AWS, de Cloudflare ou de Meta, rappellent régulièrement l’impact financier colossal des interruptions de service. Investir dans la fiabilité via le SRE n’est plus une dépense optionnelle, mais une assurance économique essentielle. Le calcul est simple : le coût de prévention (embaucher des SREs, mettre en place de l’automatisation) est infiniment inférieur au coût d’une panne majeure.

Cas Concrets & Retours d’Expérience : Le DevOps et le SRE en Action
L’adoption du DevOps et du SRE n’est pas théorique. Elle a été éprouvée et raffinée par des entreprises leaders, devenant un pilier de leur succès opérationnel. Leurs implémentations illustrent parfaitement la puissance de ces approches.
Netflix : La Culture du Chaos Engineering
Netflix, avec des centaines de millions d’utilisateurs streamant du contenu simultanément, ne peut se permettre aucune interruption. Leur approche SRE est centrée sur une pratique radicale : le chaos engineering.
-
Concrètement : L’équipe SRE de Netflix exécute en permanence des tests de résilience en production. Ils utilisent des outils internes comme Chaos Monkey, qui termine aléatoirement des instances de production, et Chaos Kong, qui simule la chute d’une région AWS entière.
-
Le Résultat : En provoquant délibérément des pannes, ils contraignent les équipes de développement à concevoir des systèmes intrinsèquement résilients, capables de tolérer les défaillances sans impact sur l’utilisateur. Cette discipline a permis à Netflix de maintenir un service extrêmement fiable malgré une architecture distribuée extrêmement complexe.
Amazon : La Vitesse Industrielle grâce au DevOps
Amazon est l’exemple même de l’échelle et de la vitesse permises par le DevOps. Leur mantra est de déployer aussi souvent que possible, chaque changement étant petit et isolé pour minimiser les risques.
-
La Preuve : Le chiffre célèbre est que Amazon effectue un déploiement en production toutes les 11,7 secondes en moyenne. Cela est rendu possible par une automatisation totale de leur pipeline CI/CD. Chaque développeur peut déployer son code de manière autonome et sécurisée.
-
Le Mécanisme : Leur culture de propriété totale (“You Build It, You Run It”) signifie que les équipes de développement sont entièrement responsables de leurs services, de l’écriture du code à sa surveillance en production. Ceci élimine le “mur de la honte” et aligne parfaitement les incitations sur la qualité et la stabilité.
Airbnb : La Fiabilité comme Expérience Utilisateur
Pour Airbnb, la fiabilité de la plateforme n’est pas une question technique, mais au cœur de l’expérience utilisateur. Un utilisateur qui ne peut pas réserver un logement à cause d’une panne perd confiance immédiatement.
-
Le Défi : Gérer des pics de charge extrêmement volatiles (comme le réveillon du Nouvel An) et garantir que des transactions financières critiques soient traitées avec une parfaite intégrité.
-
La Solution SRE : Airbnb a construit une culture de la mesure basée sur les SLOs. Ils définissent des objectifs de fiabilité très stricts pour leurs services critiques (comme le moteur de recherche et le processus de réservation) et utilisent agressivement leur budget d’erreur pour gérer le rythme des innovations. Leurs ingénieurs SRE ont développé une plateforme de monitoring sophistiquée pour visualiser en temps réel la santé de tous leurs services par rapport à ces SLOs, permettant une réaction aux incidents en quelques secondes.
Ces trois géants démontrent que le DevOps et le SRE ne consistent pas à appliquer une checklist d’outils. Netflix a institutionalisé la résilience par le chaos, Amazon a industrialisé la vitesse par l’automatisation, et Airbnb a érigé la fiabilité en métrique business prioritaire. Leur succès prouve que ces disciplines, lorsqu’elles sont pleinement adoptées, deviennent un avantage compétitif décisif.

Défis & Pièges à Éviter : Au-Delà des Outils, la Transformation Humaine et Organisationnelle
L’adoption de DevOps et de la pratique SRE (Site Reliability Engineering) présente des défis et des pièges courants qui, si eux ne sont pas anticipés, peuvent compromettre leur succès. Un des principaux défis réside dans la transformation organisationnelle, car l’adoption de DevOps est souvent freinée par la résistance au changement des structures et processus existants, ainsi que par un manque de ressources en temps et en expertise. Les pièges les plus fréquents incluent une définition floue des rôles et responsabilités au sein des équipes, ce qui laisse les membres deviner qui fait quoi et à quel moment. Cette absence de clarté peut entraîner des conflits et une inefficacité, surtout si les équipes ne sont pas correctement formées aux outils et aux processus.
Un autre piège majeur est la focalisation excessive sur les outils sans une véritable transformation culturelle. Configurer des infrastructures comme GitLab intégré avec Mattermost, Ansible, Docker/Kubernetes, ou des templates GitLab CI/CD est une bonne base, mais cela ne garantit pas une amélioration de la qualité du produit ou une réduction du « Time-To-Market ». Les outils seuls ne sont pas suffisants ; il est essentiel d’impliquer toutes les équipes dès le début du projet, de favoriser la collaboration et de constituer une équipe DevOps dédiée. La communication entre les équipes doit être adaptée aux nouveaux processus et outils, car une mauvaise communication peut nuire à l’efficacité du cycle de développement.
Un autre piège à éviter est de déployer automatiquement en production sans une vérification rigoureuse du workflow et de la sécurité, même si les tests en environnement de développement et de test semblent concluants. Les processus automatisés peuvent masquer la complexité sous-jacente, et il est préférable de retarder une livraison que de découvrir des problèmes majeurs en production. La supervision des applications web est cruciale pour détecter rapidement les anomalies, les pics de charge ou les pannes de disponibilité, surtout dans des environnements dynamiques comme le cloud.
Enfin, il est possible d’avoir à la fois des équipes DevOps et SRE au sein d’une même organisation, car elles sont complémentaires. SRE peut être vue comme une implémentation spécifique de la philosophie DevOps, avec un accent particulier sur la fiabilité. Les équipes de développement et SRE partagent un même pool de personnel, ce qui crée un système d’auto-régulation où les développeurs sont incités à produire un code plus fiable pour réduire la charge de travail des SRE. Cela met fin aux conflits d’effectifs traditionnels entre les équipes de développement et opérationnelles. En résumé, pour réussir, il faut combiner une culture de collaboration, une définition claire des rôles, une formation adéquate, une supervision efficace et une intégration harmonieuse des pratiques DevOps et SRE

Quel est l’effet des initiatives SRE sur DevOps ?
SRE et DevOps sont couramment utilisés ensemble dans les organisations et peuvent avoir un effet positif l’un sur l’autre. Habituellement, DevOps fournit un cadre pour gérer le développement de logiciels et l’exploitation de services logiciels, et SRE aide l’organisation à se concentrer sur des objectifs opérationnels spécifiques.
Réduire les silos organisationnels
L’approche SRE considère les opérations comme un problème d’ingénierie logicielle. Cela signifie que les ingénieurs travaillent à résoudre des problèmes de fiabilité qui n’étaient auparavant pas pris en compte dans la responsabilité du développement ou des opérations.
SRE favorise la responsabilité conjointe de la stabilité et des performances du système. Il aide l’organisation à créer des processus et des outils systématiques pour détecter et répondre aux défauts logiciels. Il adopte une approche axée sur les objectifs, ce qui amène l’organisation DevOps à définir clairement et à améliorer continuellement des mesures telles que le temps de chargement, le temps de détection et de résolution et l’apparition de défauts de production.
Accepter l’échec comme normal
Les équipes SRE ne se contentent pas de souligner les lacunes des processus opérationnels et de transférer la responsabilité aux autres membres de l’équipe. Ils créent plutôt un cadre pour une réduction efficace de ces déficiences. Le processus SRE utilise le concept de budget de risque, qui permet aux organisations d’avancer rapidement en matière d’innovation, tout en laissant une marge d’erreur. SRE suppose également que l’innovation continue n’est pas compatible avec des objectifs de performance et de disponibilité à 100 %.
Une perspective SRE nécessite une forte collaboration entre l’informatique et l’entreprise lors de l’évaluation des cibles optimales pour les indicateurs de niveau de service (SLI) et les objectifs de niveau de service (SLO). Chaque violation doit renvoyer une boucle de rétroaction aux équipes informatiques. En outre, les objectifs doivent être réévalués et optimisés en fonction de l’évolution des circonstances informatiques et commerciales. Le cadre SRE nécessite une enquête post mortem irréprochable sur les incidents de défaillance.
Mettre en œuvre un changement progressif
Comme DevOps, SRE favorise l’amélioration continue. Pour faciliter cet aspect, le SRE nécessite que les changements soient petits et fréquents. Idéalement, cette approche devrait garantir que les répercussions négatives ont moins d’impact et aider les équipes à tester et à mettre en œuvre rapidement des améliorations à faible risque.
Pour mettre en œuvre un changement progressif, les équipes SRE utilisent des tests automatisés, généralement dans le cadre du pipeline CI/CD. Idéalement, les mesures objectives du changement devraient être définies de manière à garantir que les objectifs opérationnels s’améliorent progressivement, tout en réduisant le coût de l’échec.
Tirer parti de l’outillage et de l’automatisation
DevOps favorise l’adoption de l’automatisation et de la technologie – et souvent, la pile technologique sera différente selon les équipes. SRE, en revanche, favorise une utilisation cohérente des outils et de la technologie dans tous les projets, car les problèmes d’intégration et l’incompatibilité des différentes technologies peuvent créer des silos inutiles.
SRE exige que toute technologie adoptée soit adaptée aux compétences de chaque équipe et de chaque domaine de service. Toutefois, cela ne signifie pas que les équipes doivent utiliser un certain ensemble d’outils pour une tâche spécifique. L’accent est principalement mis sur la normalisation—garantissant que tous les outils et leurs activités ITSM associées peuvent être gérés par la même API ou le même cadre d’automatisation.

Tendances Futures & Innovations
Alors que le DevOps et le SRE deviennent matures, de nouvelles pratiques émergent pour adresser leurs limites et pousser plus loin l’automatisation, l’intelligence et l’efficacité. Ces innovations ne remplacent pas le DevOps, mais le prolongent et l’enrichissent pour faire face aux défis de demain.
- GitOps L’infrastructure et les Déploiement pilotés par Git
Le Concept : Étendre les principes DevOps en utilisant Git comme source de vérité unique et centralisée non seulement pour le code applicatif, mais aussi pour l’infrastructure et la configuration des déploiements.
Comment ça marche ?
-
La state désirée de l’infrastructure (Kubernetes, cloud) est décrite dans des fichiers de déclaration (YAML, Helm charts) versionnés dans un dépôt Git.
-
Un opérateur (comme ArgoCD ou Flux) surveille en permanence le dépôt et le cluster. Dès qu’un changement est détecté, il synchronise automatiquement l’état réel du cluster avec l’état déclaré dans Git.
-
Tout changement doit passer par une pull request, permettant ainsi la revue de code, l’audit trail et la réversibilité (il suffit de revert un commit pour annuler un déploiement).
Pourquoi c’est puissant ?
-
Audit et Traçabilité Complets : Qui a changé quoi, quand et pourquoi ? L’historique Git répond à tout.
-
Sécurité et Conformité : Les processus de validation et d’approbation sont intégrés naturellement dans le workflow Git.
-
Consistance et Fiabilité : Élimine la dérive de configuration (“configuration drift”) entre environnements.
-
2. AIOps : L’intelligence Artificielle au Service des Opérations
Le Concept : Exploiter le machine learning (ML) et l’intelligence artificielle (IA) pour automatiser la détection, l’analyse et la résolution des incidents, et pour optimiser les performances des systèmes.
Applications Concrètes :
Détection Anomalies Intelligente : Au lieu de seuils d’alertes statiques, des algorithmes apprennent le comportement normal d’un système et alertent sur des déviations subtiles et multivariées, souvent signes avant-coureurs d’un incident.
Corrélation Automatique des Incidents : En cas de panne, l’AIOps peut analyser des terabytes de logs, métriques et traces en quelques secondes pour identifier la cause racine commune, épargnant des heures de investigation manuelle.
Résolution Autonome (“Self-Healing”) : Pour des problèmes connus et répétitifs (ex: redémarrer un pod défaillant, scale up un service sous charge), le système peut déclencher des actions de remediation sans intervention humaine.
Optimisation des Coûts et des Performances : Recommander des tailles d’instance optimales, identifier les ressources sous-utilisées, prédire les pics de charge.
Outils Emergents : Dynatrace, Splunk ITSI, Moogsoft, et les grandes clouds (AWS DevOps Guru, Google Cloud’s Operations Suite) intègrent déjà des capacités AIOps.
3. FinOps: La Maitrise Collaborative des Couts Cloud
Le Concept : Une culture et une pratique managériale qui rassemble la tech, la finance et le business pour gérer et optimiser les coûts cloud, en alignant les dépenses sur la valeur business délivrée.
Les Piliers du FinOps :
-
Informations (Inform) : Avoir une visibilité en temps réel sur les coûts, par projet, équipe, service, afin de responsabiliser les “acheteurs” (les développeurs). Des outils comme AWS Cost Explorer, Google Cloud Billing ou CloudHealth sont cruciaux.
-
Optimisation (Optimize) : Mettre en place des actions concrètes : arrêter les ressources inutilisées, réserver des instances, choisir les types de machines les plus rentables, optimiser l’allocation du stockage.
-
Opération (Operate) : Intégrer la dimension coût dans les processus DevOps :
-
Intégrer les coûts dans les tableaux de bord à côté des métriques de performance.
-
Faire des revues de coûts lors des rétro
-

Conclusion: Vers une Fusion Humain-Machine
Le DevOps et le SRE ne sont pas de simples méthodologies techniques ou des collections d’outils à implémenter. Ils incarnent une transformation profonde de la culture organisationnelle, des processus métier et de la philosophie même du développement logiciel. Leur essence réside dans la fusion synergique entre la créativité humaine et la puissance de l’automatisation, une alliance qui redéfinit les frontières de l’innovation technologique.
Au-delà de la technique : une nouvelle philosophie de collaboration
L’héritage le plus durable du DevOps et du SRE n’est pas Jenkins, Kubernetes ou les SLOs, mais la destruction des silos et l’avènement d’une culture de responsabilité partagée. Les développeurs comprennent désormais les implications opérationnelles de leur code, tandis que les ingénieurs SRE utilisent leurs compétences pour permettre une livraison rapide et sûre. Cette collaboration, alimentée par une boucle de feedback continue, crée un environnement où l’on apprend collectivement des échecs, où l’on célèbre les succès et où l’on place la résilience au cœur de chaque décision.
L’automatisation comme prolongement de l’intelligence humaine
L’automatisation n’est pas une fin en soi, mais le moyen de libérer les équipes des tâches fastidieuses et répétitives pour leur permettre de se concentrer sur ce qui compte : la résolution de problèmes complexes, l’innovation et la création de valeur business. Les pipelines CI/CD, l’Infrastructure as Code et les systèmes auto-réparateurs ne remplacent pas les humains — ils amplifient leurs capacités. Ils permettent aux équipes de déployer des changements en toute confiance, de surveiller des systèmes d’une complexité inimaginable il y a encore dix ans et de réagir aux incidents avec une précision chirurgicale.
Se préparer aux défis de demain
Adopter le DevOps et le SRE, c’est bien plus que moderniser sa stack technique. C’est se préparer aux exigences futures :
Des architectures toujours plus complexes (edge computing, IoT, systèmes distribués à l’échelle planétaire) qui nécessiteront une orchestration et une supervision avancées.
Une demande croissante de rapidité et de personnalisation de la part des utilisateurs, qui exigera des cycles de livraison encore plus courts sans compromis sur la qualité.
La gouvernance des coûts cloud (FinOps) et la durabilité environnementale, qui deviendront des critères de décision techniques majeurs.
L’intégration de l’intelligence artificielle (AIOps) pour anticiper les pannes et optimiser les performances.
Vers une informatique humaine, résiliente et responsable
Le futur ne appartient pas aux machines, mais aux organisations qui sauront cultiver l’intelligence collective de leurs équipes tout en tirant parti de la précision infatigable des systèmes automatisés. Le DevOps et le SRE posent les fondations de cette symbiose : une informatique où l’humain reste aux commandes pour définir la vision, la stratégie et l’éthique, tandis que la machine exécute avec une efficacité et une fiabilité sans précédent.
Adopter ces approches, c’est embrasser une vision où la technologie n’est plus une contrainte, mais un levier au service de l’innovation business, de l’expérience utilisateur et de la résilience organisationnelle. C’est accepter que la seule constante est le changement, et s’armer culturellement et techniquement pour non seulement y survivre, mais en tirer parti.

“Le futur ne se configure pas. Il se versionne, se déploie et se surveille.”
Références et Lectures Complémentaires :
Kim, G., et al. (2021). The DevOps Handbook.
Beyer, B., et al. (2016). Site Reliability Engineering.
Forsgren, N., et al. (2018). Accelerate.
AWS DevOps Blog, Google SRE Resources.
« Introducing Google’s Site Reliability Engineering », Google Cloud Blog. https://cloud.google.com/blog/products/gcp/introducing-site-reliability-engineering
« What is DevOps? », Amazon Web Services. https://aws.amazon.com/devops/what-is-devops/
Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (2016). Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media.
L’Expertise derrière l’Article
Djelika Bocar Cisse, Stagiaire chez Mali Développeur SARL, j’allie expertise technique et vision stratégique pour décrypter les tendances émergentes.
Pour plus d’informations voici mon LinkedIn

