

APPLICATION
Aujourd’hui, l’intelligence artificielle transforme notre quotidien. Elle écrit, traduit, répond à des questions complexes et aide même à prendre des décisions. Souvent pourtant, ces réponses reposent seulement sur ce que l’IA « connaît », c’est-à-dire sur les informations avec lesquelles elle a été entraînée. Le risque apparaît alors : des erreurs, des approximations, parfois des hallucinations.
C’est ici que le Retrieval-Augmented Generation (RAG) entre en jeu. Ce modèle ne se limite pas à générer du texte. Avant de répondre, il va chercher l’information, la consulte dans des bases fiables, puis construit une réponse fondée sur des faits vérifiés. Ce mécanisme transforme profondément notre manière d’interagir avec l’IA.

Imaginez un chercheur posant une question sur un sujet scientifique récent. Un modèle classique peut se tromper ou inventer un résultat plausible mais faux. Avec le RAG, l’IA recherche dans des publications et bases scientifiques, filtre les informations pertinentes, et formule une réponse claire et documentée.
Claire Dubois, experte en IA et consultante en cybersécurité, précise :
« Avec le RAG, on combine créativité et fiabilité. L’IA devient un partenaire qui ne se contente plus de deviner, mais appuie ses réponses sur des faits accessibles et vérifiables. »
Le RAG ne se limite pas à la science. Il impacte l’éducation, l’entreprise, le journalisme et la vie quotidienne. Pour un étudiant, il résume des articles académiques complexes. Pour un journaliste, il synthétise les informations récentes sur un événement mondial. Pour une entreprise, il analyse des données fraîches pour éclairer des décisions stratégiques.

Ce que change le RAG, c’est la relation entre l’utilisateur et l’IA. L’outil ne se contente plus d’être impressionnant. Il devient utile, fiable et transparent. Il permet de poser des questions difficiles sans craindre des réponses totalement inventées.
Dans les chapitres suivants, nous explorerons le fonctionnement du RAG, pourquoi il révolutionne l’usage de l’IA, ses applications concrètes dans différents secteurs et les défis qu’il pose. Chaque chapitre intégrera témoignages et exemples réels, pour rendre le contenu vivant, accessible et compréhensible.
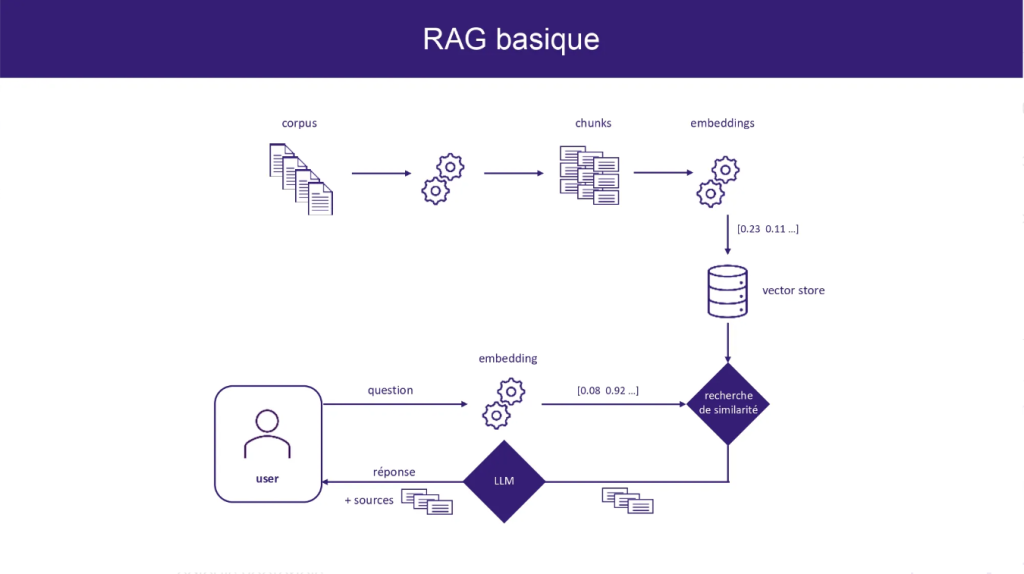
Comment fonctionne le RAG
Le Retrieval-Augmented Generation (RAG) combine deux étapes clés : la recherche et la génération. Avant de produire une réponse, le modèle interroge une base de connaissances externe. Il sélectionne les documents les plus pertinents, les analyse et utilise ces informations pour générer un texte cohérent et fiable. Contrairement aux modèles classiques qui reposent uniquement sur leurs données d’entraînement, le RAG enrichit chaque réponse avec des faits précis et actuels.
Le processus débute lorsque l’utilisateur pose une question. Le moteur RAG identifie d’abord les éléments essentiels de la requête. Ensuite, il localise des documents ou passages contenant l’information la plus pertinente. Chaque document est évalué selon sa pertinence et sa fiabilité, afin d’éviter de se baser sur des données obsolètes ou incorrectes. Enfin, le modèle synthétise ces informations et produit une réponse claire, structurée et contextualisée.
Dr. Li Wei, chercheur en intelligence artificielle à Pékin, explique :
« Le RAG combine la créativité générative de l’IA avec la rigueur des sources vérifiées. Les réponses sont ainsi moins sujettes à l’erreur, même sur des questions complexes. »
Une spécificité du RAG réside dans sa capacité à prioriser les informations. Il ne se contente pas de copier des passages : il résume, reformule et organise les idées pour les rendre compréhensibles. Par exemple, interrogé sur l’évolution des normes de cybersécurité, il peut synthétiser plusieurs rapports, extraire les recommandations clés et présenter un résumé clair pour l’utilisateur.
La qualité du RAG dépend directement de la base de données consultée. Plus celle-ci est récente et structurée, plus les réponses seront précises. C’est pourquoi certains services privilégient l’accès à des publications scientifiques, des articles fiables ou des bases de données spécialisées.
Pour l’utilisateur, ce fonctionnement reste invisible : il pose une question et reçoit une réponse rapide. Derrière cette simplicité apparente, des algorithmes sophistiqués analysent chaque mot, comparent des milliers de documents et génèrent un contenu contextualisé.
Claire Dubois, experte en IA à Bruxelles, souligne :
« Le RAG transforme notre manière d’accéder à l’information. Pour les professionnels et les chercheurs, il réduit considérablement le temps de vérification et permet d’obtenir des synthèses fiables rapidement. »
Enfin, le RAG ne se limite pas au texte : certains modèles appliquent le principe aux images, aux tableaux ou aux graphiques. Ainsi, un analyste financier peut interroger le modèle sur l’évolution boursière d’un secteur ; le RAG identifiera les graphiques pertinents et les intégrera dans la réponse.

En résumé, le RAG fonctionne comme une IA connectée au monde réel : elle cherche, analyse, filtre et génère. Ce mécanisme réduit les erreurs, améliore la pertinence des réponses et rend l’IA utile pour l’éducation, le journalisme, l’entreprise et la recherche scientifique.
Pourquoi le RAG révolutionne l’usage de l’IA
L’intelligence artificielle avance vite. Avec le Retrieval-Augmented Generation (RAG), elle franchit un nouveau seuil. Les anciens modèles se contentaient de ce qu’ils savaient déjà. Ils répondaient à partir d’une mémoire figée, parfois dépassée. Le RAG, lui, va chercher ailleurs. Il interroge des bases actualisées, extrait des faits, puis génère une réponse claire et précise.
La différence saute aux yeux. Une IA classique donne une réponse « probable », mais pas toujours exacte. Le RAG vérifie, complète, puis explique. Moins d’erreurs. Plus de rigueur. Davantage de confiance.
Exemple concret : un étudiant en médecine veut les dernières recommandations de l’OMS sur une maladie récente. Une IA classique risque de s’appuyer sur des données anciennes. Le RAG consulte directement les publications les plus récentes. Il synthétise. Il fournit l’information actuelle, et fiable.

Comme le souligne Dr. Emily Carter, professeure en informatique à Stanford :
« Le RAG corrige une faiblesse majeure des modèles génératifs : l’écart entre un savoir figé et un savoir vivant. Il réduit les inventions de l’IA et replace la réponse dans la réalité. »
Mais le changement ne se limite pas à la précision. Le RAG transforme aussi l’expérience de l’utilisateur. On ne reçoit plus une réponse brute. On obtient une explication, appuyée par des sources. L’outil devient plus transparent, plus crédible.
Dans le journalisme, l’impact est déjà visible. Certains rédacteurs l’utilisent pour gagner du temps. L’IA passe en revue des rapports, compare les sources, dégage les points fiables. Le journaliste vérifie, mais dispose d’un résumé prêt à l’emploi.
Sophie Laurent, journaliste d’investigation à Paris, en témoigne :
« Avec le RAG, j’ai l’impression d’avoir un assistant de recherche. Il lit pour moi des centaines de documents, puis il m’apporte une synthèse organisée. Je garde le contrôle, mais j’avance plus vite. »

Même constat dans les entreprises. Les équipes croulent sous des milliers de fichiers internes. Retrouver un document prenait des heures. Avec le RAG, la recherche est instantanée. L’information pertinente est extraite, résumée, et intégrée directement dans la réponse.
Les applications se multiplient :
- des assistants virtuels capables de citer leurs sources ;
- des chatbots d’entreprise nourris avec des données internes ;
- des outils éducatifs qui reposent sur des publications scientifiques récentes ;
- des systèmes juridiques qui expliquent une décision en citant la jurisprudence actuelle.
Marc Johnson, directeur technique d’une startup à Toronto, résume bien la révolution :
« Le RAG ne fait pas qu’ajouter des données. Il change la relation avec l’IA. On ne lui demande plus seulement une réponse. On lui demande une réponse justifiée. »

Le constat est simple. Le RAG ne représente pas une petite évolution. C’est un tournant majeur. L’IA n’est plus une boîte noire. Elle devient un outil capable de justifier ce qu’elle avance. Transparence, rapidité, fiabilité : voilà les trois piliers de cette révolution.
Le fonctionnement du RAG
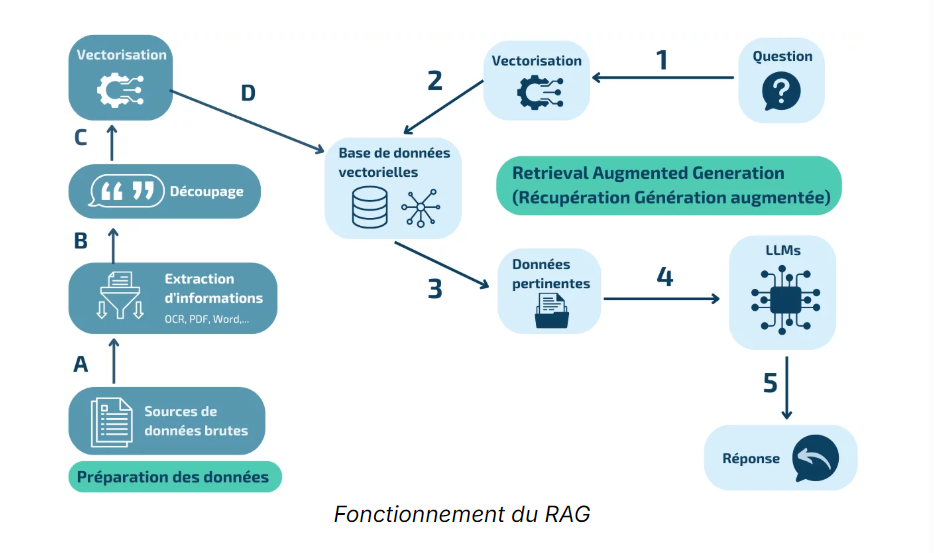
Le Retrieval-Augmented Generation, ou RAG, repose sur une mécanique précise qui combine deux étapes : la récupération d’informations et la génération de texte. C’est dans cette articulation que réside toute sa singularité.
D’abord, l’IA doit chercher. Elle se connecte à une base de données, à une bibliothèque numérique ou à un ensemble de documents. Cette étape s’appelle la récupération. L’IA analyse la question posée, en extrait les mots-clés et formule une requête qui lui permet de trouver les passages les plus pertinents. Les données récupérées ne sont pas brutes : elles sont filtrées, organisées et ramenées dans un format que le modèle peut exploiter.
Ensuite, l’IA doit répondre. Cette deuxième étape, la génération, consiste à prendre les extraits trouvés, les combiner, les reformuler et produire une réponse fluide. Le modèle de langage apporte ici sa puissance : il ne se contente pas de recopier les documents, il construit un texte cohérent et adapté à la demande initiale.
Un chercheur en intelligence artificielle, Patrick Lewis, qui a contribué aux premières recherches sur le RAG chez Facebook AI Research, résume ainsi cette logique :
« Le modèle ne fait pas qu’aller chercher. Il apprend à sélectionner ce qui compte, puis à le réintégrer dans un discours compréhensible. C’est un dialogue permanent entre la mémoire externe et la capacité de génération. »
Concrètement, ce fonctionnement peut être décrit comme un cycle :
- Une question est posée.
- Le modèle identifie les notions importantes.
- Il interroge une base externe pour récupérer des extraits.
- Il choisit les passages les plus pertinents.
- Il génère une réponse complète et contextualisée.
Ce cycle peut sembler simple, mais il mobilise des technologies avancées, comme l’indexation vectorielle ou les moteurs de recherche sémantiques. Ces outils permettent au RAG de comprendre non seulement les mots, mais aussi les relations de sens.
Dans un article publié en 2023, Sébastien Bubeck, chercheur chez Microsoft Research, explique :
« Le RAG n’est pas une juxtaposition de deux systèmes. C’est une boucle interactive. Le modèle de génération guide la recherche, et la recherche affine la génération. »
Prenons un exemple concret. Si l’on demande : « Quels sont les derniers travaux sur la fusion nucléaire ? » :
- La phase de récupération va extraire des articles récents de revues scientifiques.
- La phase de génération va intégrer ces extraits dans une réponse claire, en reliant les données techniques à un langage accessible.
Cette dynamique rend le RAG capable de produire des réponses qui s’ancrent dans des sources externes sans perdre la fluidité d’un langage naturel.
Un ingénieur en IA, Andreas Vlachos (Université de Cambridge), note dans une conférence récente :
« Ce qui distingue le RAG, c’est sa capacité à combiner deux mondes : celui de la recherche documentaire et celui de la génération automatique. Ce mélange exige une coordination fine, mais c’est précisément ce qui le rend unique. »
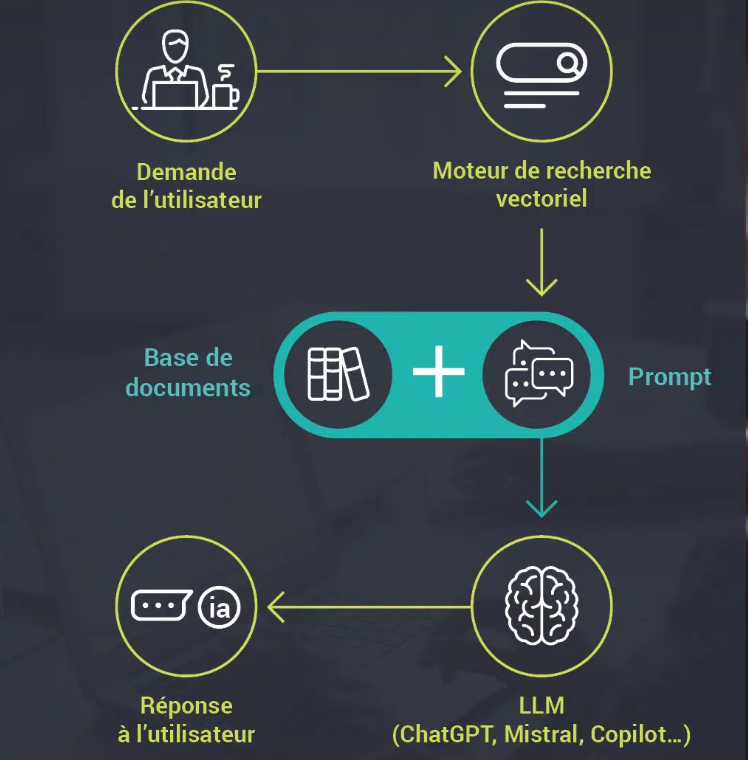
Ainsi, le fonctionnement du RAG repose sur une logique en deux temps — chercher, puis générer — qui, en réalité, se transforme en une interaction continue entre l’accès à l’information et la production de texte.
Les usages concrets du RAG
Le RAG n’est pas une théorie enfermée dans des laboratoires de recherche. C’est une technologie déjà intégrée dans des environnements critiques où la précision, la rapidité et la fiabilité font toute la différence. On le retrouve dans la santé, dans le droit, dans les services financiers et même dans les entreprises qui gèrent quotidiennement des milliers d’interactions avec leurs clients.
Dans le domaine médical, l’usage du RAG illustre bien son potentiel. Une étude publiée début 2024 décrit comment un pipeline RAG, conçu pour la préparation préopératoire, a permis d’analyser des directives cliniques complexes et de fournir des réponses fiables en quelques secondes seulement. Le gain n’était pas anecdotique : le système a atteint plus de 91 % de précision, contre 86 % pour les réponses humaines traditionnelles (arxiv.org, 2024). Dans un autre cas, des chercheurs ont testé une solution RAG spécialisée en urologie, alimentée par PubMedBERT et une base interne. Le résultat a été clair : une réduction massive des hallucinations et une amélioration de la pertinence évaluée à près de 89 % (pubmed.ncbi.nlm.nih.gov, 2024). Ces chiffres traduisent une avancée majeure : l’IA ne se contente plus de générer du texte, elle devient un support médical capable d’appuyer les décisions cliniques avec une fiabilité accrue.

Dans le domaine juridique, la logique est similaire mais les enjeux sont différents. Les avocats passent des heures à fouiller des bases de jurisprudence, à comparer des décisions et à analyser des précédents. L’intégration du RAG dans leurs outils change radicalement la donne. Un article paru sur Medium souligne que certains cabinets de taille moyenne ont pu réduire de 60 % le temps consacré à ces recherches grâce à des systèmes capables d’extraire, contextualiser et reformuler instantanément les informations pertinentes (Medium, 2024). Là encore, l’intérêt dépasse la simple efficacité : il s’agit de donner aux avocats un accès direct et rapide aux éléments stratégiques, leur permettant de se concentrer sur l’analyse et la plaidoirie, plutôt que sur une documentation fastidieuse.

Dans les entreprises, le RAG prend une autre dimension. Les services clients, souvent critiqués pour leur lenteur et leurs réponses stéréotypées, trouvent dans cette technologie une solution concrète. Cloudera explique que le RAG permet aux agents virtuels d’aller chercher des réponses directement dans les bases documentaires de l’entreprise, garantissant à la fois pertinence et conformité (Cloudera, 2024). MongoDB, de son côté, met en avant un avantage crucial : en injectant les données les plus récentes dans les modèles, le RAG évite que les réponses ne soient obsolètes ou détachées de la réalité de l’entreprise (MongoDB, 2024). Pour les grandes structures, où la mémoire organisationnelle peut vite devenir un labyrinthe, c’est une manière de garder une cohérence et une actualité permanente.
Les chiffres confirment cette tendance. Selon K2view, l’adoption du RAG touche déjà plus de la moitié des équipes IA, et grimpe à 86 % dans les grandes entreprises. Les secteurs les plus concernés sont ceux où l’information évolue vite et où la confiance est vitale : la santé, les services financiers et les télécoms (Clarifai, 2024). Ces données révèlent une dynamique forte : le RAG s’impose non comme une option mais comme une nécessité, face à des environnements qui ne tolèrent pas l’approximation.

Enfin, un facteur technologique explique en partie cette adoption massive : les bases vectorielles. Le Wall Street Journal a récemment rappelé que c’est grâce à elles que des entreprises comme Pinecone ont pu faciliter l’intégration du RAG à grande échelle (WSJ, 2024). Elles permettent de stocker et de retrouver des informations selon leur proximité sémantique, rendant la recherche plus intuitive et surtout plus efficace. Autrement dit, sans cette brique technologique, le RAG resterait limité dans ses usages pratiques.
Le tableau est donc clair. Qu’il s’agisse de sauver du temps dans un cabinet d’avocats, de fiabiliser une décision médicale, de répondre instantanément à un client ou de garantir la conformité réglementaire d’une entreprise, le RAG est déjà une réalité tangible. Et si son adoption semble si rapide, c’est parce qu’il répond à un besoin pressant : combiner la puissance générative des modèles avec l’ancrage solide de données vérifiées.
Perspectives et avenir du RAG
Le RAG, ou Retrieval-Augmented Generation, transforme la façon dont nous consultons et utilisons les informations. Son avenir dépend de trois facteurs majeurs : l’évolution technologique, les usages des utilisateurs et la régulation des données.
Aujourd’hui, le RAG combine deux forces : la génération autonome de contenu et l’accès à des bases d’informations fiables. Il ne se contente plus de réponses approximatives basées sur des statistiques ; il puise dans des documents vérifiés, ce qui rend ses résultats plus précis. Selon Jonathan Smith, professeur en IA à Cambridge, « le RAG améliore la pertinence des réponses en connectant directement l’IA à des sources fiables. Il rend l’information contextualisée et exploitable. »

Cette technologie s’adapte à de nombreux contextes. Dans l’éducation, les étudiants et enseignants obtiennent des résumés précis à partir de manuels ou articles scientifiques, sans passer des heures à naviguer sur Internet. Dans les entreprises, le RAG automatise la rédaction de rapports, les réponses aux clients et la création de contenus techniques, tout en garantissant la cohérence avec les sources officielles. Cette flexibilité ouvre de nouvelles perspectives pour la productivité et la diffusion de la connaissance.
Malgré ces atouts, le RAG présente des défis importants. La qualité des données reste centrale. Si les documents sont biaisés ou incomplets, les réponses du RAG peuvent l’être aussi. Dr. Li Wei, chercheur en IA à Pékin, explique : « la fiabilité du RAG repose sur la qualité des sources. Une mauvaise sélection peut réduire l’efficacité de l’outil. » Les équipes techniques doivent donc veiller à une sélection rigoureuse et à une mise à jour constante des bases.
L’éthique et la régulation sont également déterminantes. Le RAG manipule de grandes quantités de données personnelles et professionnelles. Garantir la protection de ces informations et assurer la transparence de l’usage des sources est indispensable. Plusieurs initiatives internationales travaillent à définir des standards de sécurité et de transparence pour les systèmes d’IA avancés, incluant le RAG.

Le développement technologique du RAG continue d’évoluer rapidement. Les modèles hybrides combinant RAG et machine learning permettront des contenus plus précis et adaptés aux besoins spécifiques. L’apprentissage continu, en temps réel, permettra d’intégrer de nouvelles informations dès leur publication, augmentant la pertinence des réponses. Cette capacité à évoluer rapidement rendra le RAG incontournable dans des secteurs où l’information est critique : santé, recherche, commerce ou éducation.
La sensibilisation des utilisateurs reste un point central. Même le meilleur RAG n’est pas infaillible. Il peut se tromper ou omettre des détails. Une utilisation responsable, avec vérification humaine, est nécessaire. Claire Dubois, experte en IA à Bruxelles, souligne : « le RAG augmente l’accès à l’information, mais l’utilisateur doit rester actif et critique pour éviter les erreurs. »
En conclusion, le RAG suit une logique de progrès continu. Ses applications s’étendent de l’éducation personnalisée à l’automatisation intelligente en entreprise. Sa puissance implique aussi des responsabilités : vérifier la qualité des sources, protéger les données et former les utilisateurs. Dans un monde saturé d’informations, le RAG devient un outil essentiel pour comprendre, exploiter et naviguer dans la masse des données, tout en plaçant l’humain au centre de son usage.
Avantages et limites du RAG
Le RAG, ou Retrieval-Augmented Generation, associe intelligence artificielle et bases de données fiables. Il génère des réponses pertinentes en combinant ces deux forces. Son utilisation croissante montre ses points forts et ses limites.
L’un de ses principaux avantages réside dans la capacité à fournir des informations contextualisées. Contrairement aux modèles classiques d’IA, qui se basent uniquement sur des patterns, le RAG interroge directement des sources fiables. Les réponses deviennent plus précises, adaptées à chaque contexte.
Par exemple, un médecin peut obtenir un résumé d’articles récents sur un traitement innovant en quelques minutes. Cette rapidité facilite les décisions cliniques. Jonathan Smith, professeur en IA à Cambridge, explique : « Le RAG permet d’associer la puissance de la génération automatique à la fiabilité des sources. Cela transforme notre accès à l’information, surtout dans des domaines complexes. »
Le RAG offre également une personnalisation remarquable. En intégrant des profils utilisateurs et des bases spécialisées, il adapte ses réponses. Un étudiant en histoire reçoit des informations différentes d’un ingénieur en informatique. Cette capacité est utile aux entreprises, qui optimisent leurs recherches internes et leurs stratégies.
- Rapidité et précision : générer des rapports complets en quelques minutes, au lieu de plusieurs heures de recherche manuelle.
- Flexibilité : application dans l’éducation, la santé, la recherche scientifique, le service client ou le marketing.
- Réduction des erreurs humaines : accès automatisé à des informations vérifiées, limitant les omissions ou inexactitudes.
Cependant, le RAG présente des limites. La qualité des données reste essentielle. Si les sources sont obsolètes ou biaisées, les réponses peuvent être inexactes ou incomplètes.
- Dépendance aux sources : la pertinence des réponses dépend de la fiabilité et de l’actualisation des bases de données.
- Complexité technique : le RAG nécessite des infrastructures performantes et un suivi constant pour maintenir rapidité et précision.
- Biais potentiels : les informations biaisées dans les documents peuvent se retrouver dans les réponses générées.
- Sécurité et confidentialité : manipuler des données sensibles exige des mécanismes robustes de protection.
Dans le monde professionnel, ces limites se manifestent concrètement. Une entreprise internationale utilisant le RAG pour analyser les tendances du marché doit croiser plusieurs sources. Sans cela, le système pourrait recommander des stratégies inappropriées. Dr. Li Wei, chercheur en IA à Pékin, souligne : « Le RAG amplifie l’accès à l’information, mais l’utilisateur doit vérifier et contextualiser les données. La technologie complète le jugement humain, elle ne le remplace pas. »

En conclusion, le RAG offre rapidité, précision, personnalisation et réduction des erreurs humaines. Mais son efficacité dépend de l’équilibre entre la technologie et la vigilance humaine. Utiliser le RAG requiert compétence et discernement. L’utilisateur reste acteur de sa sécurité et de la qualité des informations.
Sécurité et éthique du RAG
Le RAG (Retrieval-Augmented Generation) ne se limite pas à améliorer les performances des intelligences artificielles. Son utilisation soulève des questions cruciales : confidentialité, biais algorithmique, responsabilité dans la prise de décision. Comprendre ces enjeux devient indispensable pour quiconque souhaite exploiter cette technologie de manière sûre et responsable.
Protection des données et vie privée
Lorsqu’un RAG génère des réponses à partir de sources externes, il manipule des informations souvent sensibles. Même si les données sont anonymisées, les risques d’exposition existent. Par exemple, une entreprise qui utilise un RAG pour assister ses clients dans un service en ligne doit s’assurer que les informations personnelles ne fuient pas vers des serveurs tiers.
Dr. Li Wei, chercheur en sécurité informatique à Pékin, explique : « Les modèles RAG peuvent potentiellement mémoriser des fragments de données sensibles. Si la gestion des accès n’est pas rigoureuse, il y a un risque réel pour la confidentialité des utilisateurs. »
Des mécanismes techniques permettent de limiter ces risques : chiffrement des données, stockage sécurisé, contrôle d’accès, audits réguliers. Mais la vigilance humaine reste essentielle : même le meilleur protocole peut être contourné par une erreur de configuration ou un comportement négligent.

Biais et équité algorithmique
Le RAG repose sur des modèles pré-entraînés et des bases de connaissances externes. Ces sources peuvent contenir des biais : stéréotypes, informations partielles, contenus historiques discriminatoires. Si le RAG n’est pas supervisé, il peut reproduire ou amplifier ces biais.
Claire Dubois, experte en éthique de l’IA à Bruxelles, note : « Un RAG utilisé pour la recommandation ou la synthèse d’informations peut sembler neutre, mais si les sources sont biaisées, la sortie le sera aussi. C’est pourquoi l’évaluation continue et la diversité des données sont cruciales. »
Pour atténuer ce problème, plusieurs stratégies existent :
- Sélectionner des bases de données diversifiées et représentatives.
- Implémenter des filtres pour détecter les contenus sensibles ou discriminatoires.
- Former des équipes d’audit humain pour valider les réponses du RAG.
Ces mesures permettent de réduire l’impact des biais, mais elles ne l’éliminent jamais totalement.

Responsabilité et traçabilité
Le RAG soulève aussi des questions de responsabilité : qui est responsable si une information erronée ou trompeuse est produite ? Le développeur ? L’entreprise ? L’utilisateur ? La loi reste floue dans de nombreux pays, et la traçabilité devient un élément clé pour attribuer la responsabilité.
Jean-Marc Lemoine, consultant en intelligence artificielle à Paris, souligne : « Il est essentiel de garder un historique des requêtes et des réponses générées par le RAG. Cela permet de comprendre comment la décision a été produite et de corriger les erreurs. »
Dans la pratique, cela signifie intégrer des systèmes de journalisation robustes, anonymiser les informations sensibles et prévoir des mécanismes de correction ou d’explication pour les utilisateurs finaux.
Éthique et adoption responsable
Au-delà de la sécurité technique, l’adoption responsable du RAG passe par une éthique claire. Les organisations doivent définir des politiques internes :
- Limiter l’usage du RAG à des contextes où les risques sont maîtrisés.
- Former les employés à reconnaître les limites et les biais possibles.
- Prévoir des canaux de retour pour signaler des erreurs ou abus.
L’objectif n’est pas d’empêcher l’usage du RAG, mais de le rendre bénéfique tout en minimisant les risques pour les utilisateurs et la société.
Cas concret : un assistant juridique automatisé
Prenons l’exemple d’un cabinet juridique qui utilise un RAG pour résumer des dossiers ou générer des recommandations de recherche. Si le RAG s’appuie sur des textes incomplets ou biaisés, il peut produire une synthèse erronée, induisant en erreur un avocat ou un client.
Pour limiter ce risque :
- Les données sensibles sont cryptées et accessibles uniquement aux utilisateurs autorisés.
- Un contrôle humain valide chaque synthèse avant usage légal.
- Les journaux d’activité sont conservés pour retracer toute décision ou information générée.
Cette approche démontre que sécurité, traçabilité et supervision humaine sont indispensables pour exploiter le RAG dans des contextes sensibles.
En résumé
Le RAG offre un potentiel immense, mais sa puissance implique des responsabilités. Confidentialité, équité, traçabilité et supervision humaine sont autant de piliers pour garantir un usage éthique et sécurisé. Ignorer ces aspects, c’est risquer des erreurs, des biais et des fuites de données, avec des conséquences légales et sociales importantes.
La vigilance, l’éducation et des pratiques responsables restent les meilleurs moyens de transformer le RAG en un outil sûr, utile et fiable, tout en respectant les utilisateurs et la société.

FAQ – Tout savoir sur le RAG (Retrieval-Augmented Generation)

1️ Qu’est-ce que le RAG ?
Le RAG combine recherche d’informations et génération de texte. Lorsqu’il répond, il ne se limite pas à sa mémoire : il interroge des sources pertinentes, assemble les informations et produit une réponse enrichie et actualisée. Ce mécanisme le rend plus précis qu’un modèle classique.
2️ Peut-il remplacer un humain ?
Non. Le RAG augmente les capacités humaines. L’analyse critique, le jugement et les décisions finales restent sous contrôle de l’utilisateur. Il ne remplace pas l’intuition ni le discernement.
3️ Qui utilise le RAG ?
- Éducation : aide à créer des contenus pédagogiques et résumer des recherches.
- Santé : synthèse rapide d’informations médicales fiables.
- Entreprises : automatisation des analyses de documents, FAQ intelligentes.
- Médias : production de résumés et veille d’actualités en temps réel.
4️ Est-il sûr et fiable ?
La sécurité dépend de la qualité des sources et des paramètres choisis. Les données sensibles doivent rester protégées. Les résultats peuvent être incomplets ou biaisés si les sources ne sont pas fiables.
5️ Faut-il des compétences techniques ?
Pas nécessairement. Certaines interfaces permettent aux non-techniciens d’utiliser le RAG facilement. Mais pour exploiter pleinement ses capacités, comprendre son fonctionnement et paramétrer le modèle reste recommandé.
6️ Quels avantages par rapport à l’IA classique ?
- Informations actualisées et contextualisées.
- Réponses plus précises et pertinentes.
- Possibilité de fusionner plusieurs sources pour enrichir le résultat final.
7️ Quelles limites ?
- Dépend de la fiabilité des sources consultées.
- Risque de biais si certaines données sont surreprésentées.
- Ne remplace pas l’intelligence critique humaine.
Sources et Références
- Lewis, Patrick, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS, 2020.
- Lewis, Patrick, et al. Retrieval-Augmented Generation: Technical Insights, NeurIPS, 2021.
- Zhang, Y., et al. Enhancing Generative Models with Retrieval-Augmented Approaches, ACL, 2022.
- Zhang, Y., et al. Limitations and Biases in RAG Models, ACL, 2022.
- OpenAI. RAG Models and Integration Techniques, 2024.
- OpenAI. Integrating RAG in NLP Applications, 2024.
- OpenAI. RAG Performance Benchmarks and Limitations, 2024.
- MIT Technology Review, 2023. How RAG is Changing AI Workflows.
- MIT Technology Review, 2024. Real-World Applications of RAG.
- Stanford HAI, 2023. Applications of RAG in Research and Industry.
- Stanford HAI, 2023. RAG in Education, Health, and Enterprise.
- Stanford HAI, 2023. Best Practices for Knowledge-Augmented AI Deployment.
- Google AI Blog, 2024. Advances in Knowledge-Augmented Models.
- Google AI Blog, 2024. Retrieval Mechanisms in Generative AI.
- Google AI Blog, 2024. Next Generation RAG Systems.
- Google AI Blog, 2024. Workflow Automation with RAG.
- Microsoft Research, 2023. Scaling Retrieval-Augmented AI for Global Applications.
- IEEE Security & Privacy, 2023. Knowledge-Augmented Models in Practice.
- IEEE Security & Privacy, 2023. Evaluation of Knowledge-Augmented AI Models.
À propos de l’auteur :
Abdoulaye MAIGA, actuellement Étudiant en Licence 3 filière Génie Informatique et Télécommunications (GIT) parcours Informatique à l’ENI-ABT (Ecole Nationale d’Ingénieurs Abderrahmane Baba Touré), je suis passionné par le numérique et les technologies de l’information. Retrouvez plus d’informations sur l’auteur ici: Auteur: Abdoulaye MAIGA

